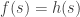Given a connected undirected graph, find its critical nodes (articulation points). A critical node is a node which its removal leaves the graph disconnected.
A straight-forward solution –to remove each node and do a DFS check for connectivity– will get an AC, but this is an implementation that uses Tarjan’s DFS algorithm for finding Articulation Point:
#include <algorithm>
#include <iostream>
#include <fstream>
#include <cstring>
#include <limits>
#include <sstream>
#include <string>
#include <stack>
#include <queue>
#include <map>
#include <set>
using namespace std;
set<int> apNodes, apVis;
set<pair<int, int> > apEdges;
void articulationPointAndBridge(map<int, map<int, int> > &graph, int s) {
// cout << "ARTICULATION POINT AND BRIDGE" << endl;
map<int, int> parent, num_dfs, num_low;
int children_s = 0, num_dfs_size = 0;
stack<int> stk;
parent[s] = s, stk.push(s);
// dfs
while (stk.size()) {
int u = stk.top();
// grey
if (apVis.find(u) == apVis.end()) {
num_dfs[u] = num_low[u] = num_dfs_size++;
apVis.insert(u);
children_s += u != s && parent[u] == s;
for (map<int, int>::reverse_iterator v = graph[u].rbegin();
v != graph[u].rend(); ++v)
// grey to white
if (apVis.find(v->first) == apVis.end())
parent[v->first] = u, stk.push(v->first);
// grey to grey
else if (parent[u] != v->first)
num_low[u] = min(num_low[u], num_dfs[v->first]);
}
// black
else {
if (parent[u] != u) {
// POINTS
if (num_dfs[parent[u]] <= num_low[u])
apNodes.insert(parent[u]);
// BRIDGES
if (num_dfs[parent[u]] < num_low[u])
if (u < parent[u])
apEdges.insert(make_pair(u, parent[u]));
else
apEdges.insert(make_pair(parent[u], u));
num_low[parent[u]] = min(num_low[parent[u]], num_low[u]);
}
stk.pop();
}
}
apNodes.erase(s);
if (children_s > 1)
apNodes.insert(s);
}
int main() {
int n;
string line;
while (cin >> n && n) {
// input
getline(cin, line);
bool inputDone = false;
map<int, map<int, int> > graph;
while (!inputDone) {
getline(cin, line);
stringstream ss(line);
int u, v;
ss >> u;
if (!u)
inputDone = true;
while (ss >> v)
graph[u][v] = 1, graph[v][u] = 1;
}
// solve
apVis.clear(), apNodes.clear(), apEdges.clear();
articulationPointAndBridge(graph, graph.begin()->first);
cout << apNodes.size() << endl;
}
}
 is iterative improvement.
is iterative improvement. is continuous. Also when we don’t know the characteristics of the target-state
is continuous. Also when we don’t know the characteristics of the target-state  (potential field) to minimize. These methods scale well to high dimensions where no other methods work. They also don’t require high storage.
(potential field) to minimize. These methods scale well to high dimensions where no other methods work. They also don’t require high storage.  and pick the best neighboring state
and pick the best neighboring state 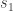 , then, from
, then, from 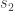 and so on… Until, we reach a state
and so on… Until, we reach a state  that is better than all its neighbors. Then we halt.
that is better than all its neighbors. Then we halt. , it picks the next state
, it picks the next state  randomly. If
randomly. If  controls the speed of convergence.
controls the speed of convergence.  should be decreasing to make sure the algorithm is more likely to halt the more it proceeds.
should be decreasing to make sure the algorithm is more likely to halt the more it proceeds.
 and an evaluation function
and an evaluation function  , the algorithm resembles A*.
, the algorithm resembles A*.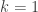 , the algorithm resembles hill-climbing which we’ll discuss in the
, the algorithm resembles hill-climbing which we’ll discuss in the  from
from 

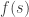 – Evaluation function. Usually, we try to go towards states that minimize this function.
– Evaluation function. Usually, we try to go towards states that minimize this function. 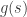 – Cost of the path
– Cost of the path  – Estimated distance from the
– Estimated distance from the 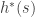 (the actual distance is often hard to determine). This is what a search algorithm produces for different choices of
(the actual distance is often hard to determine). This is what a search algorithm produces for different choices of 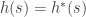

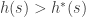
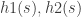 are two admissible functions and
are two admissible functions and  for all
for all 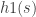 .
.